TED-culture: Culturally Inclusive Co-Speech Gesture Generation for Embodied Social Agents
A cross-cultural gesture dataset and diffusion-based model that teaches robots to gesture like locals.


Abstract
Generating natural and expressive co-speech gestures for conversational virtual agents and social robots is crucial for enhancing their acceptability and usability in real-world contexts. However, this task is complicated by strong cultural and linguistic influences on gesture patterns, exacerbated by the limited availability of cross-cultural co-speech gesture datasets. To address this gap, we introduce the TED-Culture Dataset, a novel dataset derived from TED talks, designed to enable cross-cultural gesture generation based on linguistic cues. We propose a generative model based on the Stable Diffusion architecture, which we evaluate on both the TED-Expressive Dataset and the TED-Culture Dataset. The model is further implemented on the NAO robot to assess real-time performance. Our model surpasses state-of-the-art baselines in gesture naturalness and exhibits rapid convergence across languages, specifically Indonesian, Japanese, and Italian. Objective and subjective evaluations confirm improvements in communicative effectiveness. Notably, results reveal that individuals are more critical of gestures in their native language, expecting higher generative performance in familiar linguistic contexts. By releasing the TED-Culture Dataset, we facilitate future research on multilingual gesture generation for embodied agents. The study underscores the importance of cultural and linguistic adaptation in co-speech gesture synthesis, with implications for human-robot interaction design.
Keywords
- Co-Speech Gesture Generation
- Human-Robot Interaction
- Social Agents
- Cultural Adaptation
- Diffusion Models
- Multimodal Dataset
- Virtual Avatars
- Humanoid Robots
Key Findings
- **Cultural familiarity raises the bar.** Users are significantly more critical of generated gestures in their native language, expecting higher quality in familiar linguistic contexts.
- **Diffusion models outperform GAN baselines.** The proposed Stable Diffusion-based model surpasses state-of-the-art baselines in gesture naturalness on the TED-Expressive Dataset.
- **Rapid cross-lingual convergence.** The model achieves rapid convergence across Indonesian, Japanese, and Italian, demonstrating strong multilingual generalisability.
- **Real-time robot deployment is feasible.** The gesture generation model was successfully implemented on a NAO robot, enabling real-time co-speech gesture performance across six languages.
- **TED-Culture fills a critical dataset gap.** The newly released TED-Culture Dataset provides culturally diverse, linguistically grounded gesture data not available in prior benchmarks.
Method
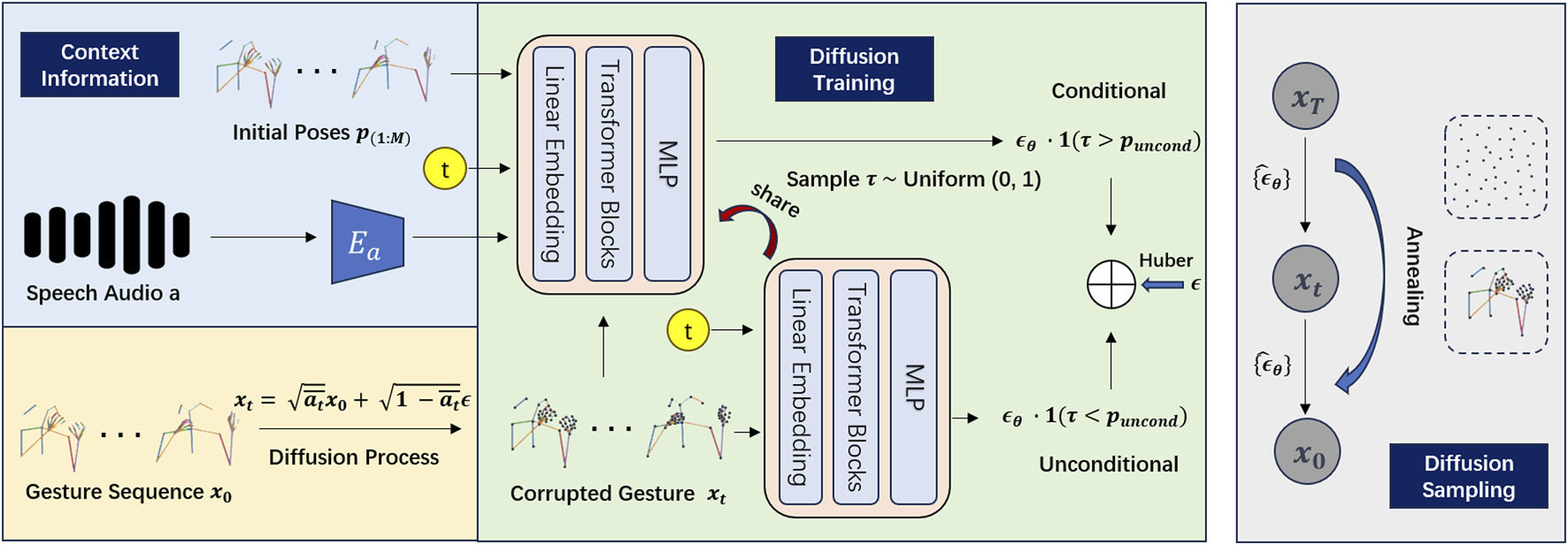
The authors introduce the TED-Culture Dataset, derived from publicly available TED talks spanning Indonesian, Japanese, and Italian speakers. Pose estimation from monocular video is used to extract upper-body keypoints and finger motion, producing a large-scale, culturally diverse dataset suitable for training cross-cultural gesture generation models. The dataset addresses limitations of prior work by combining speaker diversity, multilingual coverage, and fine-grained finger motion data.
The generative model builds on the DiffGesture framework, adapting the Stable Diffusion architecture for the gesture generation domain. The model takes linguistic cues (speech audio and text) as conditioning inputs and generates sequences of upper-body and finger joint poses. This diffusion-based approach avoids common GAN failure modes such as mode collapse and training instability, while producing diverse and naturalistic gesture outputs.
For embodied deployment, the generated gesture sequences are retargeted to the NAO humanoid robot. A mapping strategy is developed to translate the model’s continuous pose outputs onto NAO’s joint configuration, including handling the robot’s limited finger actuation. The full pipeline is evaluated both objectively (quantitative motion metrics) and subjectively (human perceptual studies), with participants from the represented cultural and linguistic backgrounds.
Results
The proposed model achieves state-of-the-art performance on the TED-Expressive Dataset, outperforming prior GAN-based and deterministic baselines in gesture naturalness metrics. On the TED-Culture Dataset, the model demonstrates rapid convergence across all three target languages — Indonesian, Japanese, and Italian — indicating strong multilingual adaptability. Subjective evaluations confirm improvements in communicative effectiveness as rated by human participants. A key finding is that native speakers apply stricter standards to gesture generation in their own language, highlighting the importance of culturally-aware evaluation. The NAO robot prototype successfully executes culturally appropriate co-speech gestures in real time across six languages, validating the practical deployment potential of the approach.
Citation
@article{shen2025tedculture,
author = {Shen, Yixin and Johal, Wafa},
title = {{TED-culture}: Culturally Inclusive Co-Speech Gesture Generation for Embodied Social Agents},
journal = {Frontiers in Robotics and AI},
volume = {12},
pages = {1546765},
year = {2025},
doi = {10.3389/frobt.2025.1546765},
publisher = {Frontiers Media SA},
website = {https://chri-lab.github.io/papers/2025-ted-culture-gesture-generation/}
}
Yixin Shen, Wafa Johal (2025). TED-culture: Culturally Inclusive Co-Speech Gesture Generation for Embodied Social Agents. Frontiers in Robotics and AI.